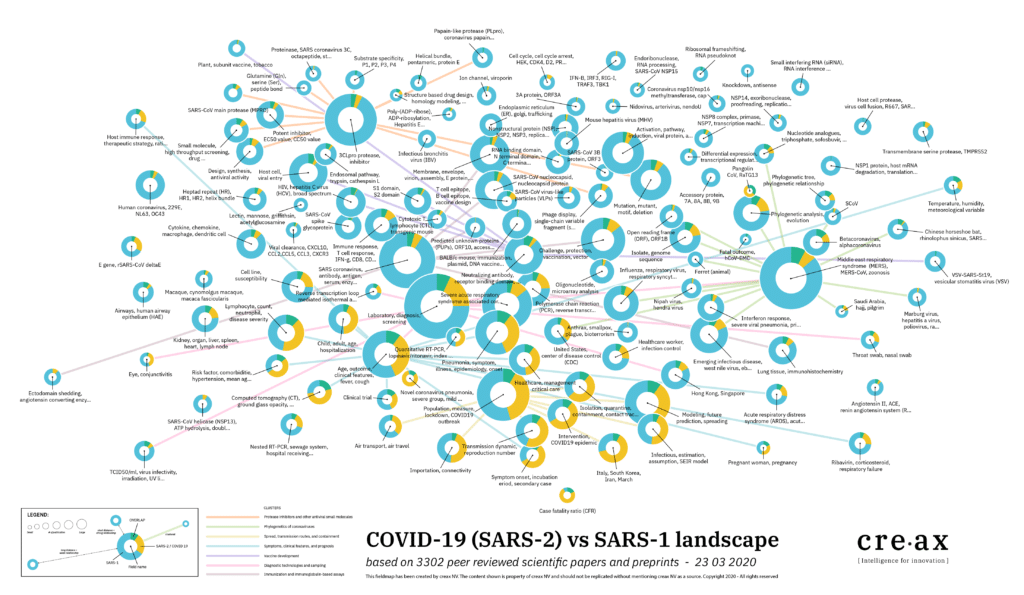
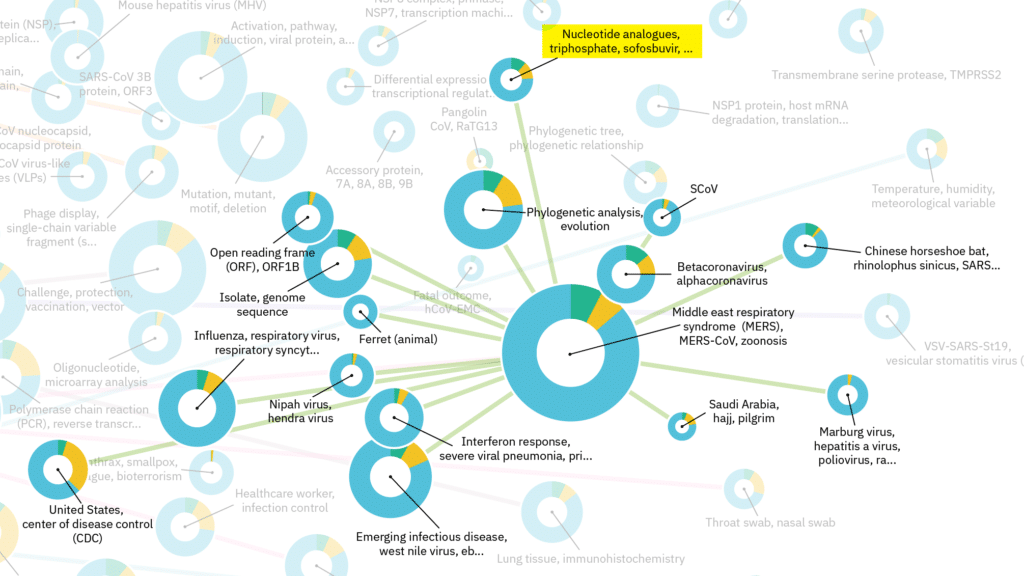
Today we live in a knowledge economy. Knowledge is abundant and available/accessible. We consult various databases to retrieve relevant information from different sources. It’s like brainstorming with the world.
Our multi-source Mynd platform structures the chaos of worldwide data and digests it into comprehensible information and insights.
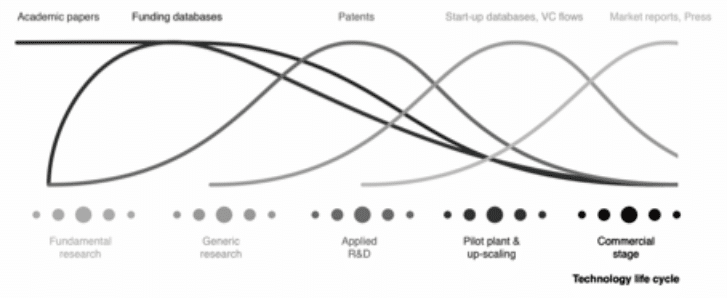
We recycle and transfer existing knowledge across industries. Our AI enabled text-mining platform retrieves relevant data from different sources, covering the entire technology lifecycle.